集合
集合及其表示
- 集合是成员的一个群集
- 成员可以是原子,也可以是集合
- 成员互不相同
- 同一集合中所有成员具有相同的数据类型
表示
- 用位向量实现
- 用有序链表实现
位向量
- 当集合是由有限的可枚举的成员组成时,可建立集合成员与整数0、1、2、…的一一对应关系,用位向量表示该集合的子集
- {red, yellow, black, white, blue}
0 1 1 0 0
有序链表
- 节点代表成员
- 成员按升序排列
- 成员可以无限增加,可以表示无穷全集合的子集
等价类与并查集
- 等价关系
- 自反性
- 对称性
- 传递性
- 一个集合所有对象通过等价关系划分成若干个互不相交的子集,这些子集是等价类
确定等价类
- 读入并存储所有等价对
- 标记和输出所有等价类
链表表示
- 每一对象:建立一个带头节点的单链表
- 一维指针数组
seq[n]作为各单链表的表头节点向量 - 第
i个单链表中所有节点的data域:等价对中与i等价的对象编号
当输入一个等价对(i, j),将i链入低j个单链表,将j链入第i个单链表
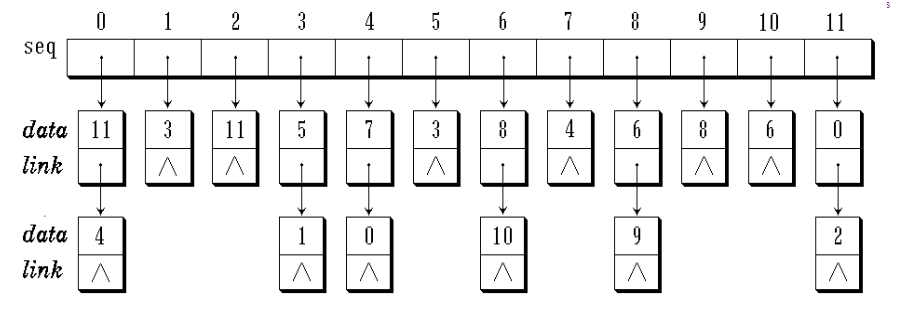
回溯用stack输出
- 时间复杂度:
- 空间复杂度:
并查集(Union-Find Sets)
- 三类操作
Union(root1, root2) //并操作Find(x) //搜索操作UFSets(s) //构造函数
- 每个集合用一棵树表示
- 采用树的双亲表示
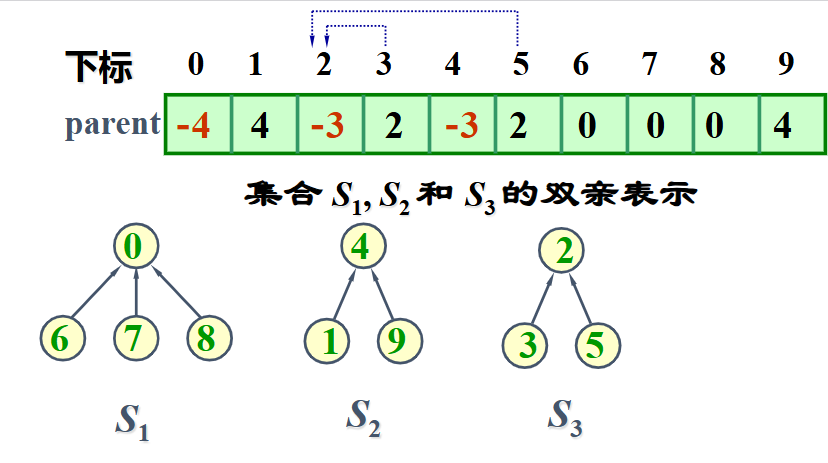
- 用
Find(i)寻找集合元素i的根。如果有两个集合元素i和 j,Find(i) == Find(j),表明这两个元素在同一个集合 - 如果两个集合元素
i和j不在同一个集合中,可用Union(i, j)将它们合并到一个集合中
1 | const int DefaultSize = 10; |
改进
按树的节点个数合并
1
2
3
4
5
6
7
8
9
10
11
12void UFSets :: WeightedUnion ( int Root1, int Root2 ) {
//按Union的加权规则改进的算法
int temp = parent[Root1] + parent[Root2];
if ( parent[Root2] < parent[Root1] ) {
parent[Root1] = Root2; //Root2中结点数多
parent[Root2] = temp; //Root1指向Root2
}
else {
parent[Root2] = Root1; //Root1中结点数多
parent[Root1] = temp; //Root2指向Root1
}
}按树的高度合并
- 高度高的树的根节点作根
压缩元素的路径长度
字典
- 有序顺序表
- 二分查找
- 有序链表
- 搜索二叉树
哈希
- 不经过比较,直接搜索
hash函数
要求
- 简单,短时间计算出结果
- 定义域必须包含需要存储的全部关键码
- 均匀分布在空间中
直接定址法
- 取关键码的线性函数值作为散列地址
- 一一映射,一般不会产生冲突,但要求散列地址空间大小与关键码集合大小相同
除余法
- 允许地址数为m,p为不大于m但最接近或等于m的素数
- 要求p不是接近2的幂
平方取中法
- 先计算构成关键码的标识符的内码的平方
- 然后按照散列表的大小取中间的若干位作为散列地址
折叠法
- 把关键码从左到右分成位数相等的几部分,每一部分对应的位数应于散列表地址位数相同。只有最后一部分位数可以短
- 数据叠加起来
- 移位法:各部分最后一位对齐相加
- 分界法:不折断而是来回折叠,对齐相加
处理冲突
- 闭散列法(开地址法)
- 线性探查法
- 二次探查法
- 双散列法
- 开散列法(链地址法)
- Title: 集合
- Author: SyEic_L
- Created at : 2025-11-14 20:05:11
- Updated at : 2025-11-14 20:05:11
- Link: https://blog.syeicl.vip/2025/11/14/集合/
- License: This work is licensed under CC BY-NC-SA 4.0.
推荐阅读

推荐阅读
Comments