第4章:网络层-数据平面
网络中的每一台主机和路由器中都有一个网络层部分
网络层能够被分解为两个相互作用的部分
- 数据平面
- 控制平面
1.网络层概述
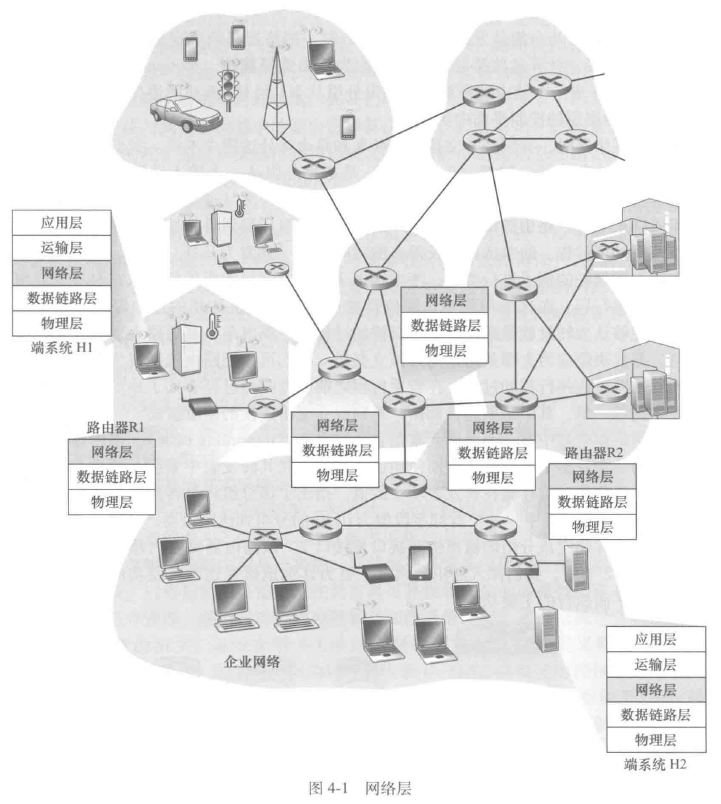
转发和路由选择:数据平面和控制平面
- 转发(forwarding):当一个分组到达某路由器的一条输入链路时,该路由器必须将该分组移动到适当的输出链路
- 路由选择(routing):当分组从发送方流经接收方时,网络层必须决定这些分组所采用的路由或路径
每台网络路由器有一个关键元素时转发表(forwarding table)。路由器检查到达分组首部的一个或多个字段值,进而使用这些首部值在其转发表中索引,通过这种方法来转发分组
控制平面:传统的方法
控制平面:SDN方法-软件定义网络(Software-Defined Networking, SDN)
网络服务模型
提供的某些可能的服务:
- 确保交付
- 具有时延上界的确保交付
- 有序分组交付
- 确保最小带宽
- 安全性
因特网的网络层提供了单一的服务,称为尽力而为服务(best-effort service)
2.路由器工作原理
- 输入端口
- 交换结构
- 输出端口
- 路由选择处理器:执行控制平面功能
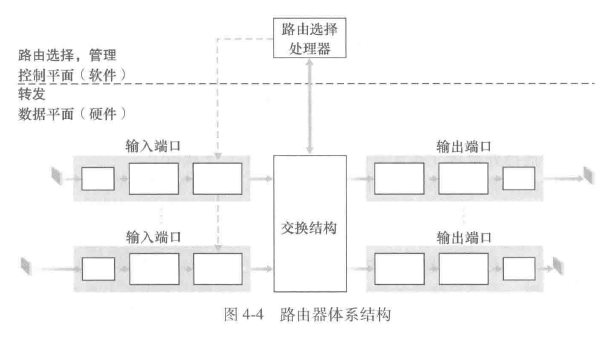
- 基于目的地转发
- 泛化转发
输入端口处理和基于目的地转发

线路端接功能与链路层处理实现了用于各个输入链路的物理层和链路层

使用这种风格的转发表,路由器用分组目的地的前缀与该表中的表项进行匹配
假设分组的目的地地址是11001000 00010111 00010110 10100001,因为该地址的21比特前缀匹配该表的第一项,所以路由器向链路接口0转发该分组
地址11001000 00010111 00011000 10101010的前24比特与表中的第二项匹配,而该地址的前21比特与表中的第三项匹配,当有多个匹配时,该路由器使用最长前缀匹配规则
查找必须在纳秒级执行,必须用硬件:实践中经常使用三态内容可寻址存储器(Tenary Content Address Memory, TCAM)来查找
一旦通过查找确定了某分组的输出端口,则该分组就能够发送进入交换结构。在某些设计中,如果来自其他输入端口的分组当前正在使用该交换结构,一个分组可能会在进入交换结构时被暂时阻塞。因此,一个被阻塞的分组必须要在输入端口处排队,并等待稍后被及时调度以通过交换结构
尽管查找在输入端口处理中可认为 时最重要的操作,但必须采取许多其他操作
- 必须出现物理层和链路层处理
- 必须检查分组的版本号、检验和以及寿命字段,并且重写后两个字段
- 必须更新用于网络管理的计数器(如接收到的IP数据报的数目)
交换
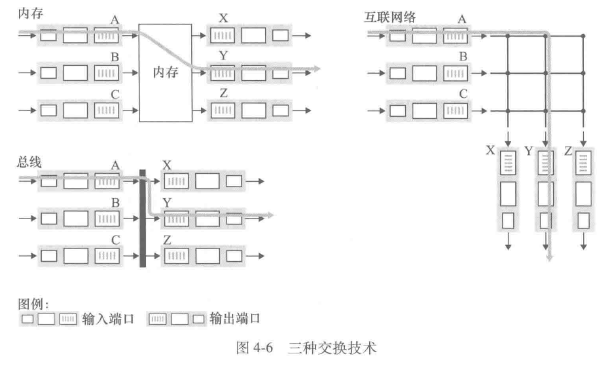
- 经内存交换:最简单、最早的路由器时传统的计算机,输入端口与输出端口之间的交换时在CPU的直接控制下完成的。许多现代路由器通过内存进行交换,与早期路由器的一个主要差别时目的地址的查找和将分组存储(交换)进适当的内存存储位置是由输入线路卡来处理的,在某些方面,经内存交换的路由器看起来很像共享内存的多处理器
- 经总线交换:输入端口经一根共享总线将分组直接传送到输出端口,不需要路由选择处理器的干预。如果多个分组同时到达路由器,每个位于不同的输出端口,除了一个分组外所有其他分组必须等待,因为一次只有一个分组能够跨越总线
- 经互联网络交换:纵横式交换机是一种由2N条总线组成的互联网络,它连接N个输入端口和N个输出端口,能够并行转发多个分组,是非阻塞的
输出端口处理
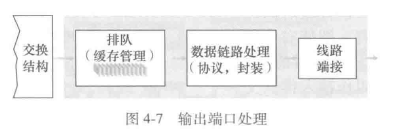
何处出现排队
随着队列的增长,路由器的缓存空间最终将会耗尽,并且当无内存可用于存储到达的分组时将会出现丢包
输入排队
交换结构不能快得(相对于输入线路速度而言)使所有到达分组无时延地通过它传送,在输入端口将出现分组排队
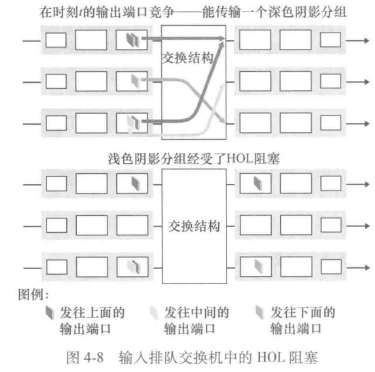
队列首部(Head-Of-the-Line, HOL)阻塞:即在一个输入队列中排队的分组必须等待通过交换结构发送,因为它被位于队列首部的另一个分组所阻塞
输出排队
当没有足够的内存来缓存一个入分组时,就必须做出决定:要么丢弃到达的分组 [采用一种称为弃尾(drop-tail)的策略],要么删除一个或多个已排队的分组为新来的分组腾出空间。在某些情况下,在缓存填满之前便丢弃一个分组的做法是有利的,这可以向发送方提供一个拥塞信号,使用明确拥塞通告比特的方法可对分组进行标记
已经提出和分析了许多分组丢弃与标记策略,统称为主动队列管理(Active Queue Management, AQM)算法
随机早期检测(Random Early Detection, RED)算法是得到最广泛研究和实现的AQM算法之一
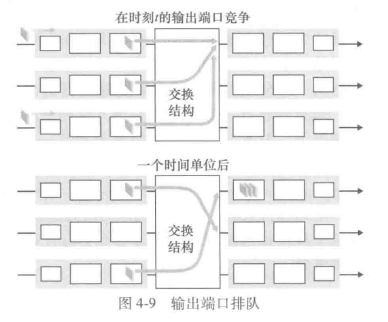
右上角的三个分组和新到的分组需要排队,输出端口的分组调度器在这些排队分组中选择一个分组来传输
多少缓存才”够用”?
当有大量的TCP流(比如N条)流过一条链路时,所需要的缓存数量是
更大的缓存区使路由器有能力承受分组到达率的更大波动,从而降低路由器的分组丢失率
但是也意味着潜在的更长的排队时延
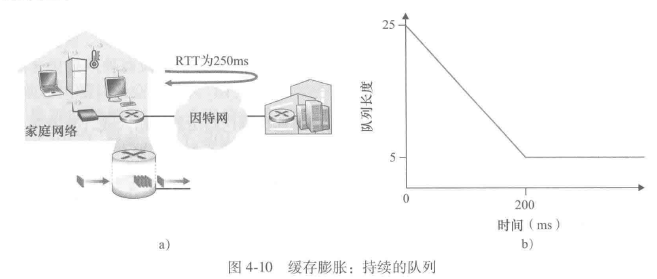
ACK定时到达使得每次一个新的分组到达队列时,队列就发送一个分组,导致家庭路由器的出链路队列长度总是5个分组,这个因持续缓冲而延长时延的场景被称为缓存膨胀
分组调度
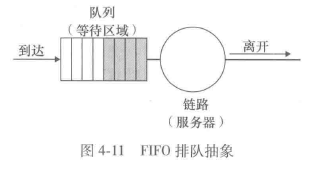
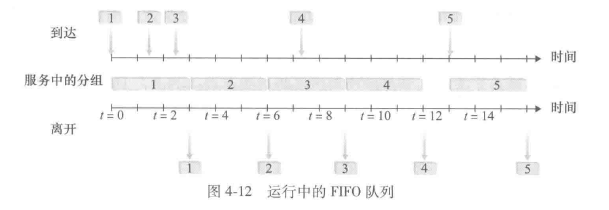
先进先出(First-In-First-Out, FIFO)
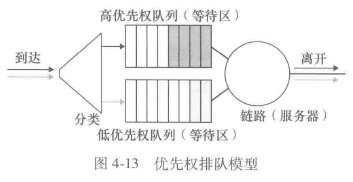
优先权排队(priority queuing)
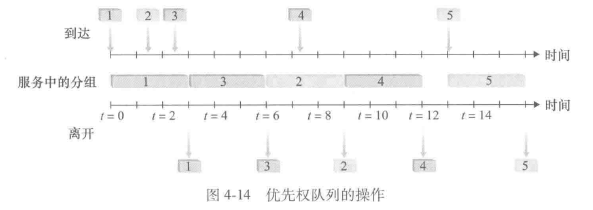
分组3和4是高优先权分组,3到达时,2还没有传输,所以先传输3,但是分组4到达时,2正在传输,在非抢占式优先权排队(non-preemptive priority queuing)规则下,一旦分组开始传输,就不能打断,因此4排队等待
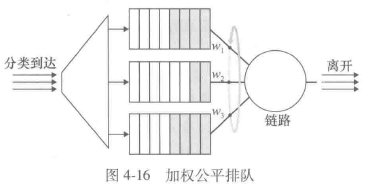
循环和加权公平排队
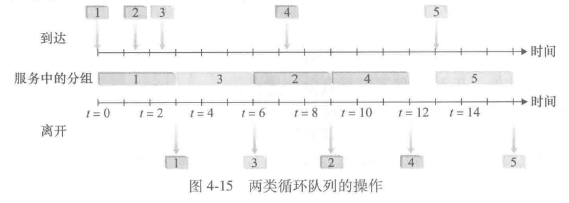
循环排队规则(round robin queuing discipline)
分组像使用优先权排队那样被分类,但类之间不存在严格的服务优先权,循环调度器在这些类之间轮流提供服务

- 分组1、2、4属于第一类
- 分组3、5属于第二类
加权公平排队(Weighted Fair Queuing, WFQ)
WFQ与循环排队的不同之处在于,每个类在任何时间间隔内可能收到不同数量的服务
对于一条传输速率为 的链路,类 总能获得至少 的吞吐量
3.网际协议:IPv4、寻址、IPv6及其他
IPv4数据报格式
- 版本:不同IP版本使用不同的数据报格式
- 首部长度:确定IP数据报中载荷实际开始的地方
- 服务类型
- 数据报长度:IP数据报的总长度(首部加上数据)
- 标识、标志、片偏移:与IP分片有关
- 寿命(Time-To-Live, TTL):确保数据报不会永远在网络中循环
- 协议:指示了IP数据报的数据部分应该交给哪个特定的运输层协议
- 首部检验和:用于帮助路由器检测收到的IP数据报中的比特错误
- 源和目的IP地址
- 选项:允许IP首部被扩展
- 数据(有效载荷)
一个IP数据报有总长为20字节的首部(假设无选项),如果数据报承载一个TCP报文段,则每个数据报共承载了总长40字节的首部以及应用层报文

IPv4编址
主机与物理链路之间的边界叫做接口(interface),路由器与它的任意一条链路之间的边界也叫做接口,一台路由器有多个接口,每个接口有其链路
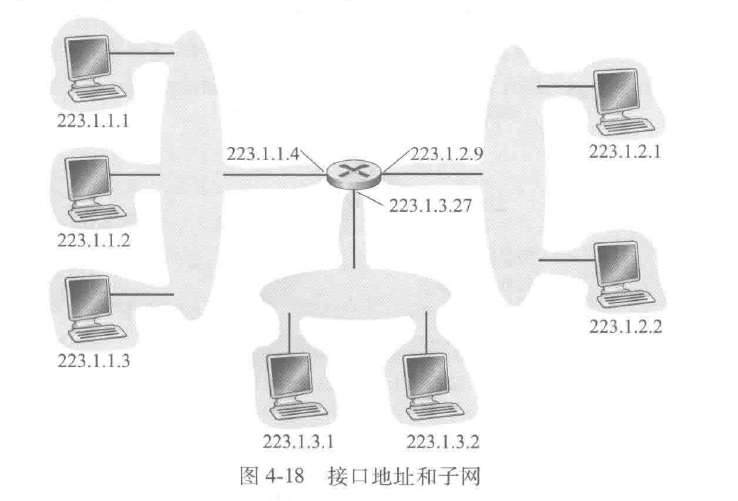
左上角的三个主机接口与一个路由器接口形成的网络形成一个子网(subnet),IP编址为这个子网分配一个地址223.1.1.0/24,其中的/24(读作slash-24)记法,有时称为子网掩码(network mask)
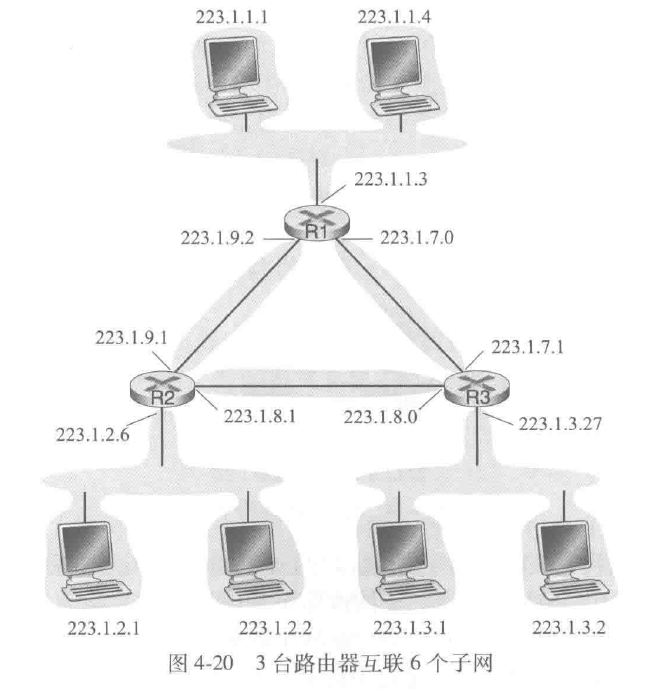
为了确定子网,分开主机和路由器的每个接口,产生几个隔离的网络岛,使用接口端接这些隔离网络的端点,这些隔离的网络中的每一个都叫做一个子网(subnet)
因特网的地址分配策略被称为无类别域间路由选择(Classless Interdomain Routing, CIDR),CIDR将子网寻址概念一般化,当使用子网寻址时,32比特的IP地址被划分为两部分 a.b.c.d/x,其中x最高比特构成了IP地址的网络部分,并且经常被称为该地址的前缀(prefix)
获取一块地址
与ISP联系,该ISP可能会从已分给它的更大地址块中提供一些地址,如下可支持8个组织

获取主机地址:动态主机配置协议
某组织一旦获得了一块地址,它就可为本组织内的主机与路由器接口逐个分配IP地址,使用动态主机配置协议(Dynamic Host Configuration Protocol, DHCP)
DHCP又称为即插即用协议(plug-and-play protocol)或零配置(zeroconf)协议
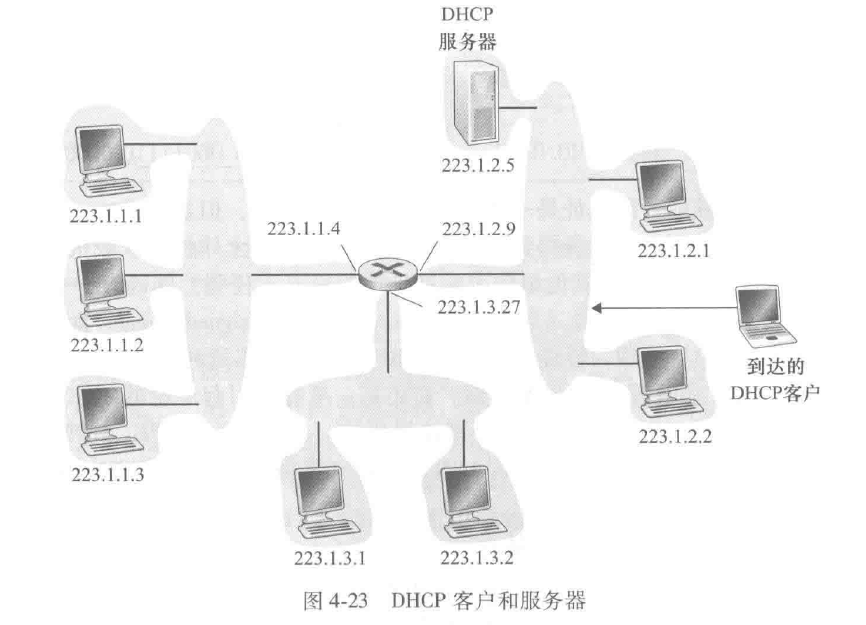
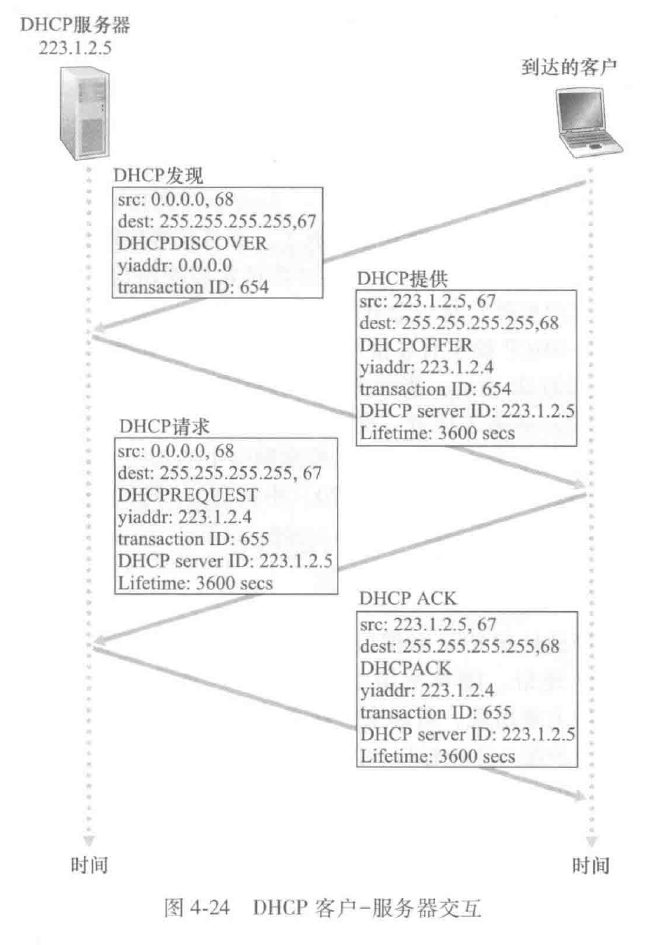
4个步骤:
- DHCP服务器发现:新到达主机通过DHCP发现报文(DHCP discover message)来完成,使用广播地址255.255.255.255
- DHCP服务器提供:DHCP服务器收到一个DHCP发现报文时,用DHCP提供报文(DHCP offer message)向客户做出响应,使用广播地址255.255.255.255
- DHCP请求:新到达的客户从一个或多个服务器提供中选择一个,并向选中的服务器提供用DHCP请求报文(DHCP request message)进行响应,回显配置的参数
- DHCP ACK:服务器用DHCP ACK报文(DHCP ACK message)对DHCP请求报文进行响应,证实所要求的参数
网络地址转换(Network Address Translation, NAT)
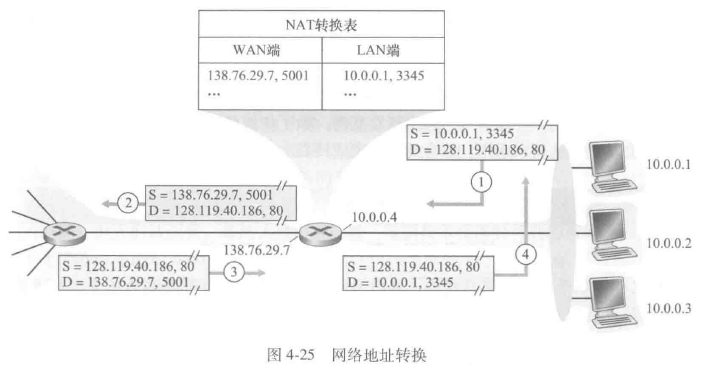
从广域网到NAT路由器的所有数据报都有相同的目的IP地址,使用NAT路由器上的一张NAT转换表(NAT translation table),并且在表项中包含了端口号及其IP地址
在P2P协议中的对等方在充当服务器时需要接受入连接,解决方案包括NAT穿越工具和通用即插即用
IPv6
IPv6引入:
- 扩大的地址容量:IP地址从32bit增加到128bit,IPv6还引入了一种称为任播地址的新型地址,这种地址可以使数据报交付给一组主机中的任意一个
- 简化高效的40字节首部:40字节定长首部
- 流标签

- 版本
- 流量类型:和IPv4中的TOS字段含义相似
- 流标签:标识一条数据报的流,对一条流中的某些数据报给出优先权,或者用来对来自某些应用(例如IP话音)的数据报给出更高的优先权
- 有效载荷长度:跟在定长的40字节数据报后面的字节数量
- 下一个首部:标识数据报中的内容需要交付给哪个协议(如TCP或UDP)
- 跳限制:与IPv4的TTL类似
- 源地址和目的地址
- 数据
以下在IPv4中出现的几个字段已经不复存在:
- 分片/重新组装:IPv6不允许在中间路由器上进行分片与重新组装,只能在源与目的地执行
- 首部检验和
- 选项:不再是标准IP首部的一部分,但并没有消失,而是可能出现再IPv6首部中由“下一个首部”指出的位置
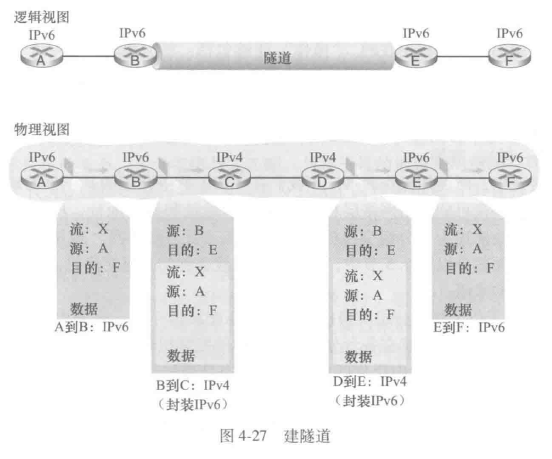
从IPv4到IPv6的迁移方法包括建隧道(tunneling),假设两个IPv6节点要使用IPv6数据报进行交互,但他们是经由中间IPv4路由器互联的,我们将两台IPv6路由器之间的中间IPv4路由器的集合称为一个隧道(tunnel)。借助于隧道,在隧道发送端的IPv6节点可将整个IPv6数据报放到一个IPv4数据报的数据字段中
4.泛化转发和SDN
匹配加操作范式
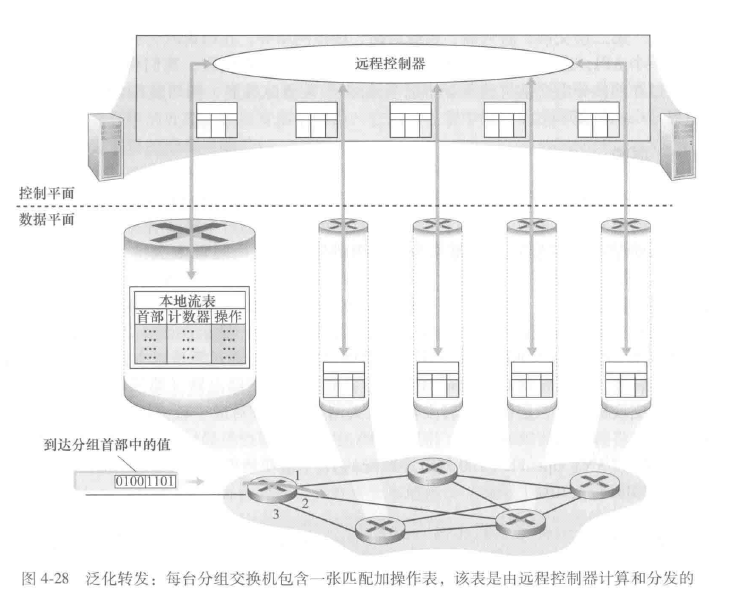
匹配加操作转发表在OpenFlow中称为流表,每个表项包括:
- 首部字段值的集合,入分组将与之匹配
- 计数器集合:可以包括已经与该表项匹配的分组数量
- 当分组匹配流表项时所采取的操作集合:可能将分组转发到给定的输出端口,丢弃该分组、复制该分组和将他们发送到多个输出端口,和/或重写所选的首部字段
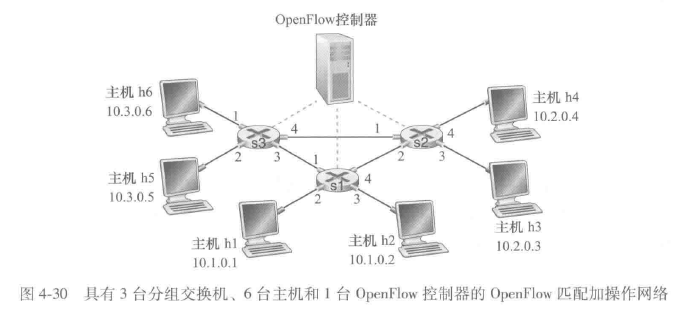
简单转发:
来自h5或h6发往h3或h4的分组从s3转发到s1,然后从s1转发到s2


- Title: 第4章:网络层-数据平面
- Author: SyEic_L
- Created at : 2026-04-20 16:24:28
- Updated at : 2026-04-20 16:24:28
- Link: https://blog.syeicl.vip/2026/04/20/第4章:网络层-数据平面/
- License: This work is licensed under CC BY-NC-SA 4.0.
