图
概念
由顶点集合和顶点间的关系集合组成的数据结构:
- V:顶点集合
- E:边集合
- :从x到y的单向通路,有方向的
有向图与无向图
- 有向图中,顶点对是有序的
- 无向图中,顶点对是无序的
完全图
- n个顶点的无向图有条边,则为完全无向图
- n个顶点的有向图有条边,为完全有向图
邻接顶点:如果是中的一条边,则u与v互为邻接顶点
子图:顶点集和边集都是子集,则图是子图
权:某些图的边具有与它相关的数(例如距离)
顶点的度
- 一个顶点v的度是与它相关联的边的条数,
- 有向图的度是出度入度之和
路径
- 路径长度
- 非带权图的路径长度为路径上边的条数
- 带权图的路径长度是路径上各边的权之和
- 简单路径:路径顶点均不互相重复
- 回路:路径上第一个顶点和最后一个顶点重合
- 路径长度
连通图与连通分量
- 无向图中,若从顶点到顶点有路径,则是连通的
- 如果图中热议一对顶点都是连通的,则此图是连通图
- 非连通图的极大连通子图叫做连通分量
强连通图与强连通分量
- 有向图中,对于每一对顶点和,都存在一条从到和到的路径,则为强连通图
- 非强连通图的极大连通子图叫做强连通分量
生成树:一个连通图的生成树是其极小连通子图,在n个顶点的情形下,有条边
存储表示
- 邻接矩阵
- 邻接表
邻接矩阵
顶点表用二维数组表示
有n个顶点的图,则邻接矩阵是
A.edge[n][n]无向图的邻接矩阵是对称的
- 第
i行1的个数是i的度
- 第
有向图的邻接矩阵可能是不对称的
- 第
i行1的个数是i的出度 - 第
j列1的个数是j的入度
- 第
网络的邻接矩阵
空间复杂度:
邻接表
无向图
同一个顶点发出的边链接在同一个边链表中,每个链节点代表一条边

有向图
邻接表(出边表)
逆邻接表(入边表)
带权图
每个链表节点带一个cost
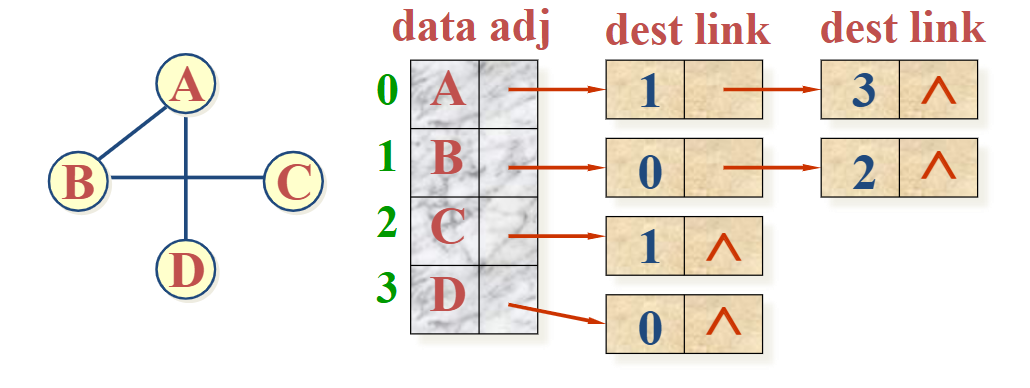
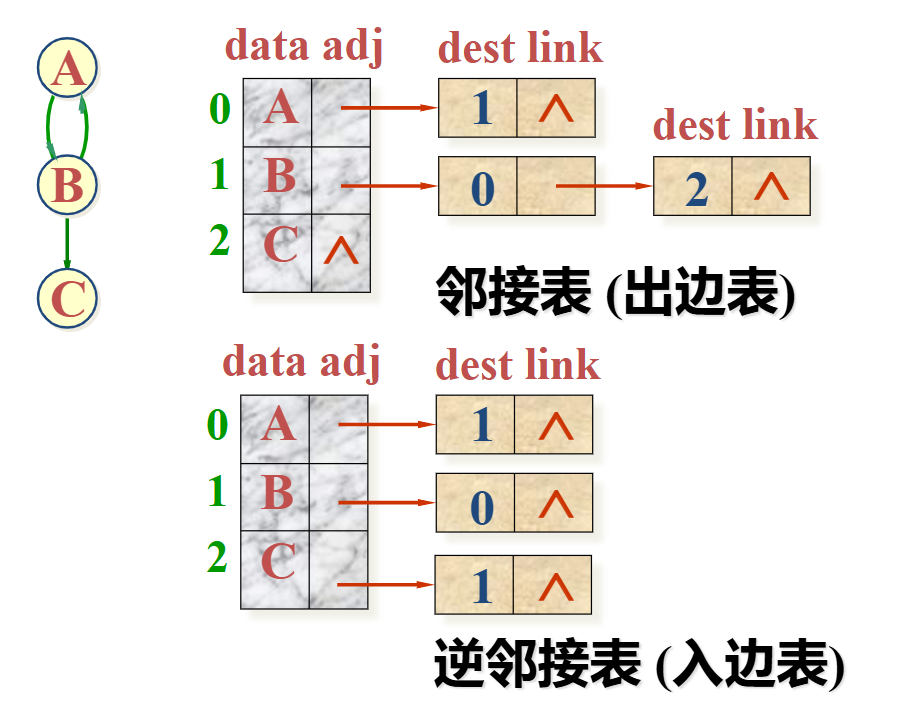
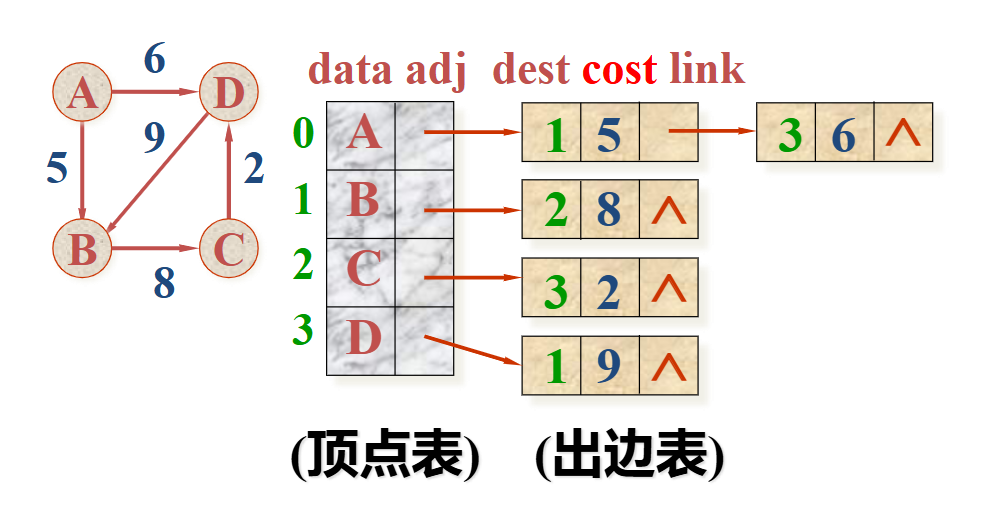
容易找到邻接点,但判断两个顶点之间是否有边不如邻接矩阵方便
基本操作
构造
- 邻接矩阵
- 构造顶点数组
- 初始化邻接矩阵
- 输入边,确定顶点在顶点数组中的位置,邻接矩阵赋值
- 邻接表
遍历
DFS
1 | //递归 |
BFS
1 | template<class Type> void BFS ( Graph <Type>& G, int v ){ |
最小生成树
- 按照生成树的定义,n个顶点的连通网络的生成树有n个顶点,n-1条边
- 构造准则
- 必须使用且仅使用网络中的n-1条边来联结网络中的n个顶点
- 不能使用产生回路的边
- 各边上的权值综合达到最小
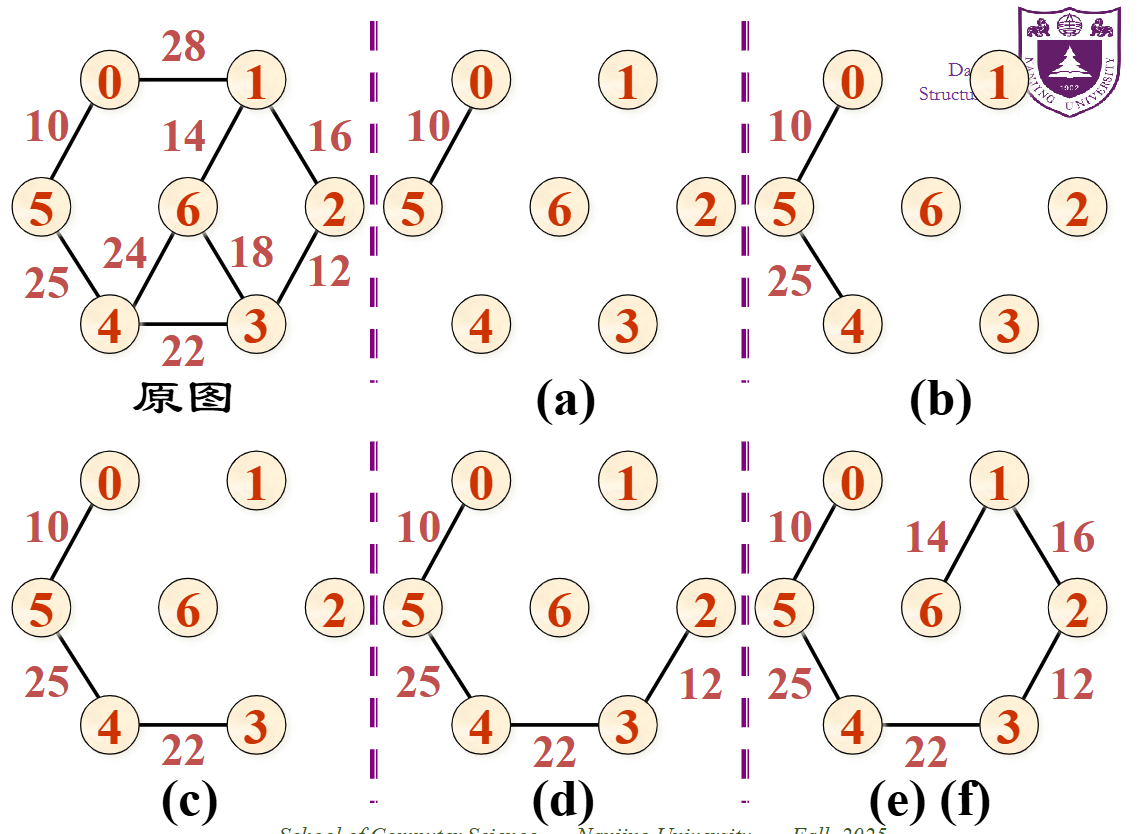
克鲁斯卡尔算法(Kruskal)
- 先构造一个n个顶点,没有边的非连通图,图中每个顶点自成一个连通分量
- 在E中选一条最小权值的边,若该边的两个顶点落在不同的连通分量上,则将此边加入到T中,否则舍去,重新选择一条权值最小的边
- 重复,直到所有顶点都在同一个连通分量上
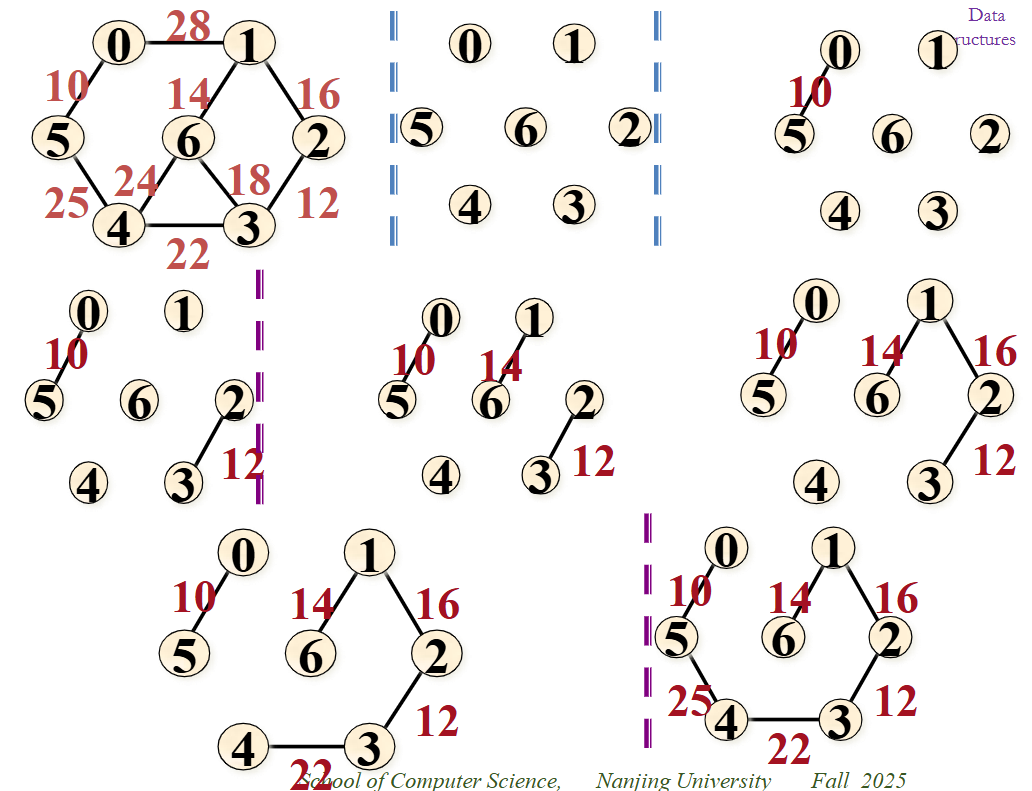
利用最小堆和并查集
堆中每个节点的格式:
tail | head | cost 两个节点位置 边的权值
检查一条边的
tail、head是否在同一连通分量上,是则舍去,否则将此边加入T,同时将两个顶点放在同一个连通分量
1 | struct DSU { |
复杂度分析
建立e条边的最小堆
总的建堆时间,检测邻接矩阵
构造最小生成树
出堆操作:e 总时间
find操作:2e 总时间
Union操作:n-1 总时间
总时间复杂度:
邻接表更好
普利姆算法(Prim)
从某一顶点出发,
每次选择一条边,这条边是所有中权最小的边,
当时,转2
1 | vector<Edge> prim(int n, const vector<vector<Edge>>& adj, int start = 0) { |
最短路径
Dijkstra算法(权值非负的单源最短路径)
引入辅助数组
dist,dist[i]表示从源点到终点的最短路径长度初始状态:
若从源点到顶点有边,则
dist[i]为边上的权值若从源点到顶点无边,则
dist[i]为
具体算法
初始化:
dist[j] = Edge[0][j], j=1,2,…,n-1求出最短路径的长度:
dist[k] = min{dist[i]},修改:
dist[i] = min{dist[i], dist[k] + Edge[k][i]},判断:
若,则算法结束,否则重复
用
path数组来记录路径时间复杂度
1 | void dijkstra(Graph<float>& G, int v, float dist[], int path[]){ |
Floyd算法
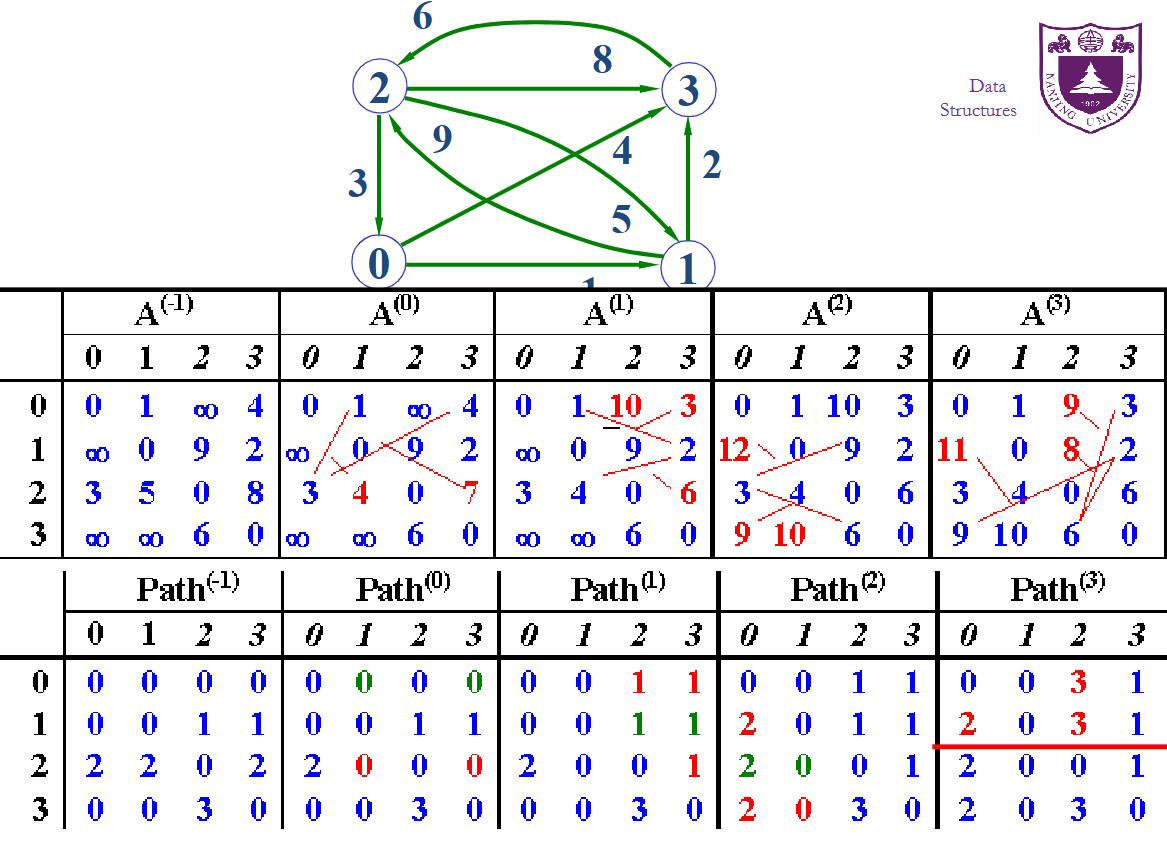
1 | void floyd(Graph<float>& G, float a[][100], int path[][100]) |
- 允许带负权值的边,但不允许包含带负权值的回路
- 时间复杂度:
活动网络
- 用顶点表示活动的网络(AOV网络):拓扑排序
- 用边表示活动的网络(AOE网络):关键路径
AOV网络
- 描述工程或系统进程
- 子工程之间存在一定的先决条件约束
拓扑排序
- 输入AOV网络,n为顶点个数
- 选一个入度为0的顶点,并输出(如果同时存在多个,随便选择一个)
- 从图中删去该顶点,同时删去所有它发出的有向边
- 重复2、3步,直到
- 全部顶点均已输出
- 或图中还有未输出的顶点,但入度不为0,说明网络中不存在有向环
算法实现
- AOV网用邻接表实现
- count:存放各顶点的入度
- 建立入度为0的顶点栈
- 顶点从0开始编号
- 每输入一条边,建立一个边节点,链入相应边链表中,统计入度信息
- 当入度为0的顶点栈不空时,重复执行:
- 从顶点栈中退出一个顶点吗,并输出
- 从AOV网络中删去这个顶点和它发出的边,边的终顶点入度减1
- 如果边的终顶点入度减至0,则该顶点进入度为0的顶点栈
- 如果输出顶点少于AOV网络的顶点个数,则报告网络中存在有向环
- 顶点栈的建立,不用额外分配存储空间,直接利用入度为0的顶点对count[]数组元素
- 顶点
i进栈时:count[i] = top; top = i; - 退栈操作:
j = top; top = count[top];
- 顶点
1 | void TopologicalSort ( Graph<Type>& G ) { |
复杂度
n个顶点,e条边
建立链式栈:
每个顶点输出一次,每条边被检查一次:
总复杂度:
AOE网络
事件顶点网络
顶点表示事件
有向边表示活动
边上权值表示活动持续时间
无环有向图
有唯一的入度为0的开始顶点
唯一的出度为0的完成顶点
工程估算
- 完成整个工程至少需要多少时间
- 缩短完成工程所需的时间,应该加快哪些活动
关键路径(critical path)
从开始顶点到完成顶点的最长
计算关键活动
- :事件的最早可能开始时间
是从源点{% _internal_math_placeholder 106 %}到顶点{% _internal_math_placeholder 107 %}的最长路径长度 - :事件的最迟允许开始时间
- :活动的最早可能开始时间
{% _internal_math_placeholder 112 %} - :活动的最迟允许开始时间
时间余量:
如果时间余量为0,则是关键活动
顺序生成数组,逆序生成数组
- Title: 图
- Author: SyEic_L
- Created at : 2026-03-12 17:41:49
- Updated at : 2026-03-12 17:41:49
- Link: https://blog.syeicl.vip/2026/03/12/图/
- License: This work is licensed under CC BY-NC-SA 4.0.
